SQL : Structured Query Language #
Description de SQL #
Langage informatique servant à exploiter des bases de données relationnelles #
Manipulation des données
- Recherche de données :
SELECT- Ajout de données :
INSERT- Modification de données :
UPDATE- Suppression de données :
DELETE
-
Définition des données
- Manipule les structures de données de la base
- Création de tables et autres structures :
CREATE - …
-
Contrôle des données et des transactions
- Gestion des autorisations d’accès aux données par les différents utilisateurs
- Gestion de l’exécution des transactions
- Transaction = suite d’opérations de modification de la base de données
SGBDR = Système de Gestion de Bases de Données Relationnelle #
- Logiciel permettant de manipuler le contenu des bases de données relationnelles
- Garantit la qualité, la pérennité et la confidentialité des informations
Exemple : SQLite  est un SGBDR dont le code source est dans le domaine public
est un SGBDR dont le code source est dans le domaine public
SQL est un langage déclaratif #
- Décrit le résultat voulu sans décrire la manière de l’obtenir
- Les SGBDR déterminent automatiquement la manière optimale d’effectuer les opérations nécessaires à l’obtention du résultat
Différents SGBDR #
-
SQLite : open source. n’utilise pas de serveur. Stocke la base dans un unique fichier. Très rapide pour des bases “modestes” (< 1 million d’enregistrements)
-
MySQL, PostgreSQL, Oracle etc. : (Oracle n’est pas open source). Utilisent un serveur. Très rapides pour des bases “conséquentes”.
La majorité de ces logiciels sont écrits en C ou en C++.
- Certains sont spécialisés (graphiques, données numériques précises etc)
- D’autres sont fournis avec un serveur dans le cloud etc.
Tous implémentent les fonctions de base de SQL + quelques fonctions “perso” parfois commodes.
SQLite #
Nous utiliserons SQLite qui est programmé en C et qu’on peut utiliser
-
en Python (
import sqlite3), -
en mode fenêtré avec DB Browser,
-
ainsi qu’en ligne.
-
ou même sur mon site Editeur et TP commande.
-
dans l’interpréteur sqlite :
$ sqlite3 sqlite> CREATE TABLE department(id INTEGER, name STRING); sqlite>
mais aussi
- iOS,
- Android etc.
À noter, toutes les applications mobiles qui enregistrent localement beaucoup de données utilisent SQLite. Ce n’est pas le seul moyen d’enregistrer quelque chose sur le téléphone : fichiers, “local storage = dictionnaire” etc.
Éléments de syntaxe SQL #
Les données utilisées dans cette partie #
Durant tout ce cours, on utilisera les mêmes données issues de deux tables.
Intéressons nous d’abord à la table
employees.Voici le code qui a permis de la créer puis de la remplir :
DROP TABLE IF EXISTS employees; CREATE TABLE employees( id integer, name text, designation text, manager integer, hired_on date, salary integer, commission float, dept integer); INSERT INTO employees VALUES (1,'JOHNSON','ADMIN',6,'1990-12-17',18000,NULL,4); INSERT INTO employees VALUES (2,'HARDING','MANAGER',9,'1998-02-02',52000,300,3); INSERT INTO employees VALUES (3,'TAFT','SALES I',2,'1996-01-02',25000,500,3); INSERT INTO employees VALUES (4,'HOOVER','SALES I',2,'1990-04-02',27000,NULL,3); INSERT INTO employees VALUES (5,'LINCOLN','TECH',6,'1994-06-23',22500,1400,4); INSERT INTO employees VALUES (6,'GARFIELD','MANAGER',9,'1993-05-01',54000,NULL,4); INSERT INTO employees VALUES (7,'POLK','TECH',6,'1997-09-22',25000,NULL,4);Un peu plus bas, nous introduirons une seconde table
departmenten relation avecemployees.Les definitions évoluent alors en :
DROP TABLE IF EXISTS department; CREATE TABLE department( id integer, name text, PRIMARY KEY("id") ); DROP TABLE IF EXISTS employees; CREATE TABLE employees( id integer, name text, designation text, manager integer, hired_on date, salary integer, commission float, dept integer, PRIMARY KEY("id"), FOREIGN KEY("dept") REFERENCES "department"("id") ); INSERT INTO department VALUES (1,"Sales"); INSERT INTO department VALUES (2,"Admin"); INSERT INTO department VALUES (3,"IT"); INSERT INTO department VALUES (4,"Foreign"); INSERT INTO employees VALUES (1,'JOHNSON','ADMIN',6,'1990-12-17',18000,NULL,4); INSERT INTO employees VALUES (2,'HARDING','MANAGER',9,'1998-02-02',52000,300,3); INSERT INTO employees VALUES (3,'TAFT','SALES I',2,'1996-01-02',25000,500,3); INSERT INTO employees VALUES (4,'HOOVER','SALES I',2,'1990-04-02',27000,NULL,3); INSERT INTO employees VALUES (5,'LINCOLN','TECH',6,'1994-06-23',22500,1400,4); INSERT INTO employees VALUES (6,'GARFIELD','MANAGER',9,'1993-05-01',54000,NULL,4); INSERT INTO employees VALUES (7,'POLK','TECH',6,'1997-09-22',25000,NULL,4);Remarquez bien les deux lignes :
De la table
departmentPRIMARY KEY("id")De la table
employeesFOREIGN KEY("dept") REFERENCES "department"("id")
Extraire des données d’une table avec
SELECT#SELECT noms_colonnes_separes_par_virgules FROM nom_table;Sélectionne toutes les lignes d’une table
Cette page présente des cellules comme celle ci-dessous, exécutables.
Vous pouvez voir le résultat de cette requête en l’exécutant. La zone de texte étant éditable, vous pouvez essayer autre chose.
Séléctionner des colonnes
Exercice #
Affichez les noms, rôles et commissions des employés.
Utiliser
*pour toutes les colonnes #SELECT * FROM nom_table;
Séléctionner toute une table
Exercice #
Ajoutez
LIMIT 5avant la fin (;) de la requête.Qu’est-ce que cela change ?
DISTINCTpour sélectionner une seule occurrence de chaque valeur de la colonne en question #SELECT DISTINCT nom_colonne FROM nom_table;
Exemple :
SELECT DISTINCT manager FROM employees;
avec et sans DISTINCT
Exercice #
Qu’obtient-on sans le mot clé
DISTINCT?
Filtrer avec
WHERE#Sélectionne uniquement les lignes qui respectent la clause du
WHERESELECT noms_colonnes_separes_par_virgules FROM nom_table WHERE nom_colonne op_comp valeur op_bool nom_colonne op_comp valeur;
WHERE
Exercice #
Affichez les noms et salaires des employés n’ayant pas reçu de commission.
On peut vérifier qu’un champ n’est pas renseigné avec
IS NULL
La clause porte sur les valeurs des colonnes #
- Utilisation d’opérateurs de comparaison (op_comp) :
=,<>,!=,>,>=,<,<= - Utilisation d’opérateurs booléens (op_bool) :
AND,ORAND: combinaisons de conditions sur des colonnes différentesOR: plusieurs valeurs possibles pour une même colonne
Exemples :
SELECT name, salary, commission FROM employees
WHERE salary > 20000 AND commission > 0;
SELECT name, salary, commission FROM employees
WHERE salary > 20000 OR commission > 0;
WHERE, opération booléennes
Exercice #
Affichez toutes les infos des employés gagnant moins de 40000 ou du département 4.
AS#Change l’affichage et le nommage des données
SELECT abrev.nom_colonne AS nom_affiche FROM nom_table AS abrev ORDER BY nom_colonne [DESC];
-
Associé à un nom de colonne : change le nom affiché de la colonne dans le résultat.
-
Associé à un nom de table : permet d’abrévier le nom de la table pour préciser de quelle table provient une colonne dont le nom est utilisé par plusieurs tables. Cette abréviation doit être utilisée dans le reste de la requête.
avec et sans AS
Fonctions de calcul sur les données extraites. #
Applique une fonction sur les valeurs d’une colonne
ORDER BY#
- Trie les données selon la colonne précisée.
- Par défaut, le tri est dans l’ordre croissant,
DESCpermet d’obtenir l’ordre décroissant.SELECT FONCTION(nom_colonne) FROM nom_table;
ORDER BY
Exercice #
Affichez les employés par département décroissant.
COUNT: compte le nombre de lignes sélectionnées.
MIN,MAX: renvoie la valeur minimum ou maximum de la colonne, parmi les lignes sélectionnées
SUM,AVG: calcule la somme ou la moyenne des valeurs numériques de la colonne, parmi les lignes sélectionnées
Salaire moyen
Exercice #
Affichez la masse salariale de l’entreprise avec un nom de colonne pertinent.
Exemple :
SELECT AVG(effectif) AS Moy_employes
FROM evolution
WHERE categorie="Employés";
Agréger avec
GROUP BY- Hors programme #
GROUP BY : agrège ensemble les valeurs identiques
d’une colonne pour appliquer une fonction à chacun des sous-ensembles
Exemple :
SELECT code, AVG(effectif) AS Moy_employes
FROM evolution
WHERE categorie="Employés"
GROUP BY code;
Calcule la moyenne des effectifs des Employés (Hommes et Femmes)
pour chaque ville.
Exemples avec ou sans agrégat #


AVERAGE et GROUP BY
Exercice #
Affichez les départements et leur salaire moyen. On utilisera un nom de colonne pertinent.
Modification des données #
Ajouter avec
INSERT#
INSERT: ajoute une nouvelle ligne de données dans une tableINSERT INTO nom_table VALUES (liste_valeurs_dans_ordre_colonnes_table); INSERT INTO nom_table (liste_nom_colonnes_a_remplir) VALUES (liste_des_valeurs_a_inserer_dans_ordre_liste_colonnes);
Insertion avant, après
Exercice #
Insérez le nouvel employé :
id Nom Désignation Encadre Recruté le Salaire Département 8 Turing Tech 6 2022/05/04 33000 3 Voir plus haut pour la description de la table
employee
Depuis une base vide, les données sont insérées de la même manière :
vide
Aparté hors programme #
Il exite une autre manière d’insérer des données, très utilisée en pratique :
INSERT INTO table SELECT ( requete de selection )Cela permet d’insérer des données en faisant référence à une autre table. C’est parfois indispensable, en particulier quand une table sert de pont entre deux tables :
Par exemple pour des commande d’une client à un vendeur, on utilise trois tables :
- client: les clients et leurs données statiques,
- vendeur: les vendeurs idem,
- commande: chaque commande avec une clé étrangère vers client et un autre vers vendeur.
Pour insérer une commande du client A au vendeur B valant x€, il faudrait connaître les identifiants du client et du vendeur.
On utilise alors
INSERT INTO commande SELECT (...)Ceci est largement hors programme et assez mal documenté sur internet.
Quelques exemples ici
Mettre à jour avec
UPDATE#
UPDATE: met à jour la ou les lignes qui respectent la clause duWHEREUPDATE nom_table SET nom_colonne1=valeur1, nom_colonne2=valeur2 WHERE nom_colonne op_comp valeur op_bool nom_colonne op_comp valeur;
UPDATE
Exercice #
Doubler le salaire de tous les employés gagnant moins de 30000$.
Effacer avec
DELETE#
DELETE: efface la ou les lignes d’une table qui respectent la clause duWHEREDELETE FROM nom_table WHERE nom_colonne op_comp valeur op_bool nom_colonne op_comp valeur;
DELETE
Exercice #
Effacer tous les employés du département 3 OU gagnant plus de 40000$.
Extraction des données de deux tables #
Lorsqu’on travaille avec plusieurs table en relation, il faut pouvoir les combiner.
Deux approches différentes :
- produit cartésien,
- utiliser les clés étrangères.
Le produit cartésien de deux ensembles est l’ensemble des couples d’éléments de ces ensembles.
P = {1, 2, 3}, Q = {A, B} P x Q = {(1, A), (1, B), (2, A), (2, B), (3, A), (3, B)}
Produit cartésien #
Comme son nom l’indique, génère de façon exhaustive toutes les associations possibles entre les lignes des deux tables
Dans le TP précédent : Nbtotal_lignes = Nb_lignes_ville * Nblignes_evolution = 650 * 10400
Cette approche est à éviter autant que possible
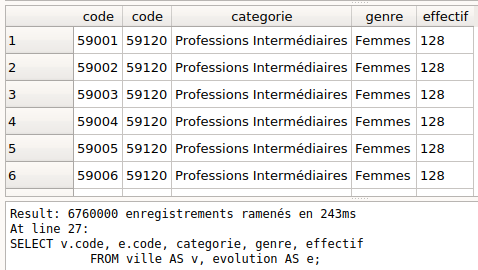
Produit cartésien
Une autre manière d’obtenir le même résultat CROSS JOIN :
CROSS, comme la croix du produit… $2 \times 3 = 6$
Produit cartésien avec CROSS
Exercice #
Affichez le nombre de lignes des tables
department,employeeset de leur produit cartésien.On utilisera plusieurs requêtes.
Mettre en relation avec JOIN ON
#
Génère uniquement les associations entre les lignes qui sont liées par des clés primaires et étrangères identiques.
Permet d’associer deux tables qui sont en relation.
C’est la notion la plus importante et la plus délicate du chapitre.
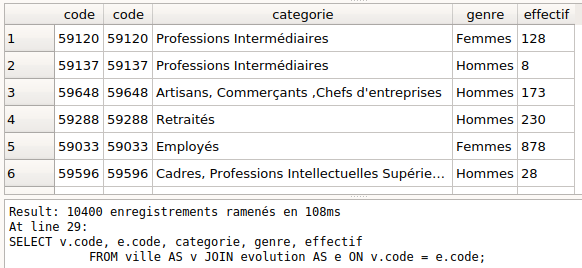
Dans l’exemple du code, employees.dept est un clé étrangère faisant référence à departement.id
On fait donc une jointure sur cette clé :
Jointure
Pour sélectionner des colonnes il convient d’utiliser le noms complets :
Jointure et sélection
Problème, deux colonnes issues de tables différentes peuvent porter le même nom. On utilise alors des alias :
Jointure et sélection
Avec un alias sur les tables on écrit la requête plus facilement :
Jointure mieux présentée
Exercice #
- Affichez les noms, salaires et département des employés, triés par date d’embauche.
- Cette fois limiter au 3 premiers résultats.
- Ne conserver que ceux qui ont touché une commission. La clause
WHEREest entreJOIN ...etORDER BY ...
Respect de l’intégrité des données #
Lorsqu’il existe une relation (clé primaire, clé étrangère) entre des tables,
on doit respecter l’intégrité des données lorsqu’on les modifie (INSERT, DELETE, UPDATE).
- Une clé primaire doit être unique et non NULL
- On ne peut pas insérer une ligne avec une clé primaire qui existe déjà.
- On ne peut pas modifier la valeur d’une clé primaire en une autre valeur qui existe déjà.
- Une clé étrangère doit référencer une clé primaire existante
- Il faut créer la ligne contenant la clé primaire avant une ligne contenant une clé étrangère la référençant.
- On ne peut pas modifier une clé primaire si elle est déjà référencée.
- On ne peut pas effacer une ligne contenant une clé primaire déjà référencée.
- Il est possible de mettre des contraintes sur les clés pour gérer les cascades de modifications (interdiction ou gestion automatique)