En bref : Le format CSV est couramment utilisé pour échanger des données habituellement traitées à l’aide de tableurs ou de logiciels de bases de données principalement. Nous allons apprendre à importer et exporter des données en utilisant ce format.
1. Données en table #
De quoi parle-t-on ?
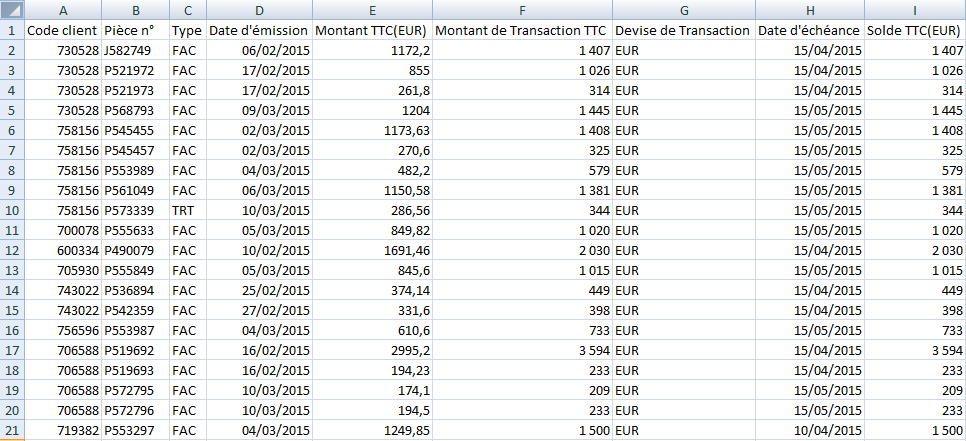
Par “données en table” on entend ce type d’information :
-
correctement importé dans un tableur
-
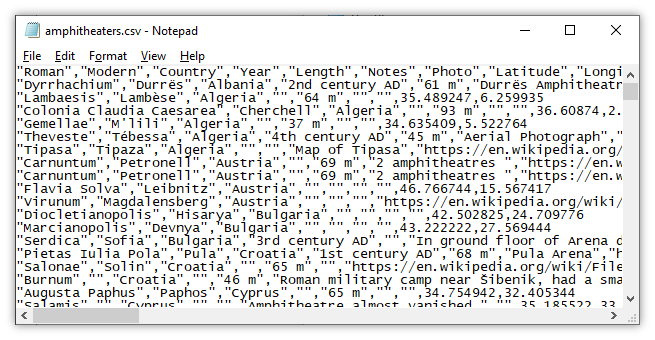
mal importé dans un tableur

-
sans mise en forme dans un fichier texte
Les tableurs évolués réalisent un traitement complexe des données mais on peut toujours exporter ou importer un tableau de données vers un fichier au format particulier.
2. Enregistrements #
-
Un enregistrement est une structure de données, de types éventuellement différents, auxquelles ont accède grâce à un nom.
Exemple : On peut représenter les notes d’un élève dans différentes disciplines à l’aide d’un enregistrement :
{'Nom' : 'Joe', 'Anglais': '17', 'Info': '18', 'Maths': '16'}Les champs (ou clés ou attributs) de ces enregistrements sont ici
'Nom','Anglais','Info'et'Maths'. On leur associe des valeurs, ici'Joe','17','18'et'16'.Dans un tableau, un enregistrement correspond à une ligne.
-
En Python, on utilisera des dictionnaires ou, plus rarement, des listes pour représenter les enregistrements.
Les données en table dans un langage de programmation #
En python, ce tableau peut prendre différentes formes :
-
Tableau doublement indexé :
contacts = [ ['Duchmol', 'Robert', 'robert@email.com',], ['Lemeilleur', 'Franky', 'franky@email.com',], ['Poivre', 'Jacques', 'jacque@email.com'] ] -
Tableau de dictionnaires :
contacts = [ {'Nom': 'Duchmol', 'Prénom', 'Robert', 'email': 'robert@email.com'}, {'Nom': 'Lemeilleur', 'Prénom', 'Franky', 'email': 'franky@email.com'}, {'Nom': 'Poivre', 'Prénom', 'Jacques', 'email': 'jacque@email.com'} ]
Le contenu ne change pas, les manipulations nécessaires pour y accéder si.
Dans certains cas on dispose directement des données (via l’énoncé ou un travail préalable). Parfois on doit importer les données depuis un fichier csv.
Comparaison des formats #
Dans le cas des double listes, on accède aux données comme dans un tableau 2D :
-
accéder au premier enregistrement.
>>> contacts[0] ['Duchmol', 'Robert', 'robert@email.com'] -
quel est le prénom du second contact ?
>>> contacts[1][1] 'Franky'
Avec une liste de dictionnaires, on accède toujours aux enregistrements par leur indice mais on accède aux valeurs par leur clés.
-
quel est le prénom du second contact ?
>>> contacts[1]['Prénom'] 'Franky'C’est plus facile à comprendre.
3. Fichiers CSV #
Le format CSV (Comma Separated Value) est couramment utilisé pour importer ou exporter des données d’une feuille de calcul d’un tableur. C’est un fichier texte dans lequel chaque ligne correspond à une ligne du tableau, les colonnes étant séparées par des virgules. Il permet donc de représenter une liste d’enregistrements ayant les mêmes champs.
À noter : Ce format est né bien avant les ordinateurs personnels et le format
xlspuisque c’est en 1972 qu’il a été introduit.
-
Pour éviter les problèmes dûs à l’absence de standardisation du séparateur décimal (virgule en France, point dans les pays anglo-saxons), on peut paramétrer son tableur pour utiliser le point pour les nombres (français suisse par exemple).
-
Voici un exemple de feuille de calcul.
A B C D 1 Nom Anglais Info Maths 2 Joe 17 18 16 3 Zoé 15 17 19 4 Max 19 13 14
Le fichier CSV correspondant est :
'Nom','Anglais','Info','Maths'
'Joe','17','18','16'
'Zoé','15','17','19'
'Max','19','13','14'
4. Lecture de fichiers CSV #
-
On peut choisir de représenter en Python les fichiers CSV par des listes de dictionnaires dont les clés sont les noms des colonnes.
-
Avec l’exemple précédent, on définit la liste :
Table1 = [ {'Nom': 'Joe','Anglais': '17', 'Info': '18', 'Maths': '16'}, {'Nom': 'Zoé','Anglais': '15', 'Info': '17', 'Maths': '19'}, {'Nom': 'Max','Anglais': '19', 'Info': '13', 'Maths': '14'} ]À noter : En utilisant le vocabulaire habituel décrivant une feuille de calcul d’un tableur :
- une table est une liste de dictionnaires: ici
Table1 - une ligne est un dictionnaire, ici
Table1[0] - une cellule est une valeur associée à une clé d’un dictionnaire, ici
Table1[0]['Info']
- une table est une liste de dictionnaires: ici
5. Import d’un fichier CSV #
La méthode à retenir #
-
pour l’import on crée une liste de dictionnaires (un par ligne de la table). La première ligne du fichier CSV est considérée comme la ligne des noms des attributs.
fichierest une chaîne de caractères donnant le nom du fichier. Par exemple :depuis_csv('Ma_base.csv')pour charger le fichierMa_base.csvimport csv def depuis_csv(fichier): with open(fichier, 'r') as contenu_csv: lecteur = csv.DictReader(contenu_csv) return [dict(ligne) for ligne in lecteur]
6. Exporter vers un fichier CSV avec Python #
-
Pour l’export, on entre le nom de la table sous forme de chaîne. On donne l’ordre des colonnes sous forme d’une liste d’attributs.
def vers_csv(nom_fichier, table, champs): with open(nom_fichier, 'w') as contenu: writer = csv.DictWriter(contenu, fieldnames=champs) writer.writeheader() ## pour la 1ere lire, celle des attributs for ligne in table: writer.writerow(ligne) ## ajoute les lignes de la table -
Pour exporter la table
tableon utilise :>>> vers_csv('Table1.csv', table, ['Nom', 'Anglais', 'Info', 'Maths'])Python crée alors un fichier
Table1.csvau format CSV :Nom,Anglais,Info,Maths Joe,17,18,16 Zoé,15,17,19 Max,19,13,14
7. Sélectionner et projeter #
On est régulièrement amené à récupérer une partie des données.
- lorsqu’on souhaite accéder à un ou plusieurs enregistrements vérifiant un critère, on réalise une sélection.
- lorsqu’on souhaite accéder à toutes les données d’une colonne on réalise une projection.
Exemple de sélection. #
Supposons qu’on dispose d’une table enregistrée dans une liste de dictionnaires :
Table1 = [
{'Nom': 'Joe','Anglais': '17', 'Info': '18', 'Maths': '16'},
{'Nom': 'Zoé','Anglais': '15', 'Info': '17', 'Maths': '19'},
{'Nom': 'Max','Anglais': '19', 'Info': '13', 'Maths': '14'},
{'Nom': 'Bob','Anglais': '12', 'Info': '16', 'Maths': '10'}
]
On souhaite extraire la liste des enregistrements des élèves ayant eu au moins 16 en maths.
C’est une sélection dont le critère est “`enregistrement[“Maths”] >= 16”
On peut le faire “à la main” :
au_moins_16_en_maths = []
for enregistrement in Table1:
if enregistrement['Maths'] >= 16:
au_moins_16_en_maths.append(enregistrement)
Le résultat est encore une table :
au_moins_16_en_maths = [
{'Nom': 'Joe','Anglais': '17', 'Info': '18', 'Maths': '16'},
{'Nom': 'Zoé','Anglais': '15', 'Info': '17', 'Maths': '19'}
]
On peut le faire avec une liste par compréhension :
au_moins_16_en_maths = [enre for enre in Table1 if enre['Maths'] >= 16]
Le résultat est identique.
Exemple de projection #
Cette fois, on souhaite récupérer toutes les valeurs pour un champ donné, par exemple toutes les notes de mathématiques.
-
à la main :
L’approche est similaire, on crée une liste, on parcourt la table et on ajoute à la liste tous les éléments qui nous intéressent :
notes_maths = [] for enregistrement in Table1: notes_maths.append(enregistrement['Maths']) -
par compréhension :
notes_maths = [enre['Maths'] for enre in Table1]
Dans les deux cas le résultat est la liste [16, 19, 14, 10]
Exercices #
-
Adapter la sélection afin de récupérer tous les enregistrements des élèves dont le nom comporte un “o”
-
Projeter afin de construire la liste des noms puis celle des paires de notes d’info et de maths :
[(18, 16), (17, 19), (13, 14), (16, 10)]
Illustration #
Téléchargez ce fichier pour disposer d’un exemple illustrant ces manipulations :
- fichier csv de départ notes.csv
- script manipulant ce fichier notes.py
- fichier csv après la modification notes_apres.csv
7. Compléments #
Cette partie est donnée pour votre culture mais n’est pas à apprendre.
Bases de données #
Le format CSV n’est pas le seul utilisé pour enregistrer des données. Il existe d’autres formats de fichiers textes mais aussi une approche beaucoup plus élaborée qui remplit le même objectif : les bases de données.
En terminale on étudiera les bases de données et en particulier le langage SQL.
Ce sont des programmes qui permettent à plusieurs utilisateurs d’accéder aux ressources, de conserver une trace de ce qui est fait sur les données etc.
Les autres formats texte #
Citons :
-
CSV, le plus couramment employé, démocratisé par Excel (Microsoft)
-
JSON (Javascript Object Notation)
{ "glossary": { "title": "example glossary", "GlossDiv": { "title": "S", "GlossList": { "GlossEntry": { "ID": "SGML", "SortAs": "SGML", "GlossTerm": "Standard Generalized Markup Language", "Acronym": "SGML", "Abbrev": "ISO 8879:1986", "GlossDef": { "para": "A meta-markup language, used to create markup languages such as DocBook.", "GlossSeeAlso": ["GML", "XML"] }, "GlossSee": "markup" } } } } }Ressemble beaucoup aux
dictde Python. -
XML (eXtensible Markup Language) - . Syntaxe similaire à l’HTML. Difficile à lire pour un “humain”.
<!DOCTYPE glossary PUBLIC "-//OASIS//DTD DocBook V3.1//EN"> <glossary><title>example glossary</title> <GlossDiv><title>S</title> <GlossList> <GlossEntry ID="SGML" SortAs="SGML"> <GlossTerm>Standard Generalized Markup Language</GlossTerm> <Acronym>SGML</Acronym> <Abbrev>ISO 8879:1986</Abbrev> <GlossDef> <para>A meta-markup language, used to create markup languages such as DocBook.</para> <GlossSeeAlso OtherTerm="GML"> <GlossSeeAlso OtherTerm="XML"> </GlossDef> <GlossSee OtherTerm="markup"> </GlossEntry> </GlossList> </GlossDiv> </glossary>
Mais aussi :
-
YAML (yet another markup language)
- martin: name: Martin D'vloper job: Developer skills: - python - perl - pascal - tabitha: name: Tabitha Bitumen job: Developer skills: - lisp - fortran - erlang
Contexe #
- Généré par un programme : souvent XML ou JSON
- Crée à la main depuis un tableur : CSV
- Utilisé par des machines pour communiquer via une API : JSON
- Pour stocker des configurations de programme : Yaml, INI, format propriétaire
Importer les données en Python sans utiliser le module CSV #
Vous rencontrerez vraisemblablement des variantes de la méthode précédente. Nous allons en présenter rapidement plusieurs. Elles ne sont pas à connaître mais à comprendre.
Créer un tableau doublement indexé #
Voyons d’abord comment réaliser chacune des étapes (c’est un attendu) puis comment le faire à l’aide des outils proposés.
CHAMPS = ["nom", "moyenne", "moyenne_brute"]
def lire_fichier_csv(filename, delimiter=','):
res = []
with open(filename) as f:
f.readline() ## on zappe la première ligne...
l = f.readline()
while l != '':
args = l.replace('"', '').strip().split(delimiter)
try:
enregistrement = []
for i in range(len(args)):
enregistrement[i] = args[i]
res.append(enregistrement)
except ValueError:
pass
l = f.readline()
return res
liste_csv = lire_fichier_csv('2nde-14-liste.csv', delimiter=';')
Commentaires détaillés sur la fonction lire_fichier_csv
#
- ligne 4 : on crée la liste des enregistrements
- ligne 5 : on ouvre le fichier et on le stocke dans une variable temporaire
f - ligne 6 :
f.readline(): lire une ligne et avancer à la suivante - ligne 7 : on a zappé la première ligne et on lit la seconde
- ligne 5 : tant qu’on a des lignes non vides
- ligne 9 : on nettoie la ligne : virer les “, les espaces de début et de fin et on sépare la ligne tous les ‘delimiter’
- ligne 10 : on essaye de créer l’enregistrement
- ligne 11 : c’est une liste python
- ligne 13 : on l’ajoute à la liste des enregistrements
- ligne 16 : si jamais la ligne est imparfaite, on la zappe
- ligne 17 : on avance à la ligne suivante
Qu’obtient-on ? #
Un tableau doublement indexé. Les descripteurs sont enregistrés dans CHAMPS.
Ils ne sont pas utilisés dans la fonction d’import.
Variante : vers un tableau de dictionnaire. #
Exercice : adapter la première fonction d’import pour qu’elle retourne un tableau de dictionnaires.
Réponse :
CHAMPS = ["nom", "moyenne", "moyenne_brute"]
def lire_fichier_csv(filename, delimiter=',', champs=CHAMPS):
res = []
with open(filename) as f:
f.readline() ## on zappe la première ligne...
l = f.readline()
while l != '':
args = l.replace('"', '').strip().split(delimiter)
try:
enregistrement = {} ## on crée un dictionnaire
for i in range(len(args)):
enregistrement[champs[i]] = args[i] ## les clés sont les éléments de CHAMPS
res.append(enregistrement)
except ValueError:
pass
l = f.readline()
return res
liste_csv = lire_fichier_csv('2nde-14-liste.csv', delimiter=';')