pdf pour impression
Structure de donnée : Dictionnaire #
1. Programme #
Contenus :
Dictionnaires, index et clé.
Capacités attendues :
Distinguer des structures par le jeu des méthodes qui les caractérisent.
Choisir une structure de données adaptée à la situation à modéliser.
Distinguer la recherche d’une valeur dans une liste et dans un dictionnaire.
2. Définition #
- Un dictionnaire est une structure de donnée gardant en mémoire des
informations de la forme
(clé, valeur). - Le but d’un dictionnaire est d’être capable d’accéder rapidement à une
valeurà partir de saclé.
3. Interface #
Dans le domaine des strucutres de données, l’interface désigne l’ensemble des opérations qui sont possibles avec cette structure de donnée.
Elle se distingue de son implantation qui désigne le programme permettant de réaliser cette structure de données.
Ainsi, en travaux dirigés, nous avons vu deux implantations différentes de cette même strucure de donnée : avec des listes et avec une table de hachage.
Une seule (avec table de hachage) étant satisfaisante.
4. Interface d’un dictionnaire #
Les avis divergent mais je considère qu’on doit pouvoir :
- Créer un dictionnaire vide.
- Mesurer un dictionnaire : combien d’entrées comporte-t-il ?
- Ajouter un couple
(clé, valeur). - Accéder à une
valeurdepuis saclé. - Retirer un couple
(clé, valeur). - Répondre à la question : ce dictionnaire comporte-t-il une entrée avec cette
clé?
On peut ajouter d’autres manipulations, en particulier :
- Itérer sur les
clés, sur lesvaleurs, sur les couples(clés, valeurs); - Vider un dictionnaire ;
- Comparer deux dictionnaires (
d1 == d2) ; - Créer un dictionnaire avec des valeurs existantes
d = {'nom': 'Minvussa', 'prenom': 'Gerard'}; - Faire une copie du dictionnaire etc.
Notons que Python propose toutes ces opérations avec le type dict.
Un exemple de programme les illustrant toutes et indiquant à quelle méthode magique ils correspondent est disponible en fin de document.
5. Implantation #
1. Table de hachage #
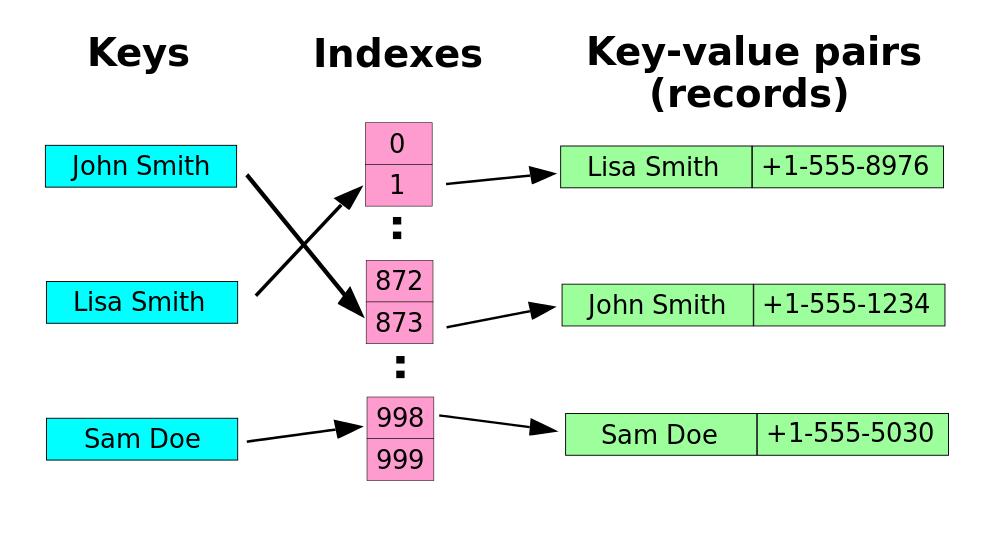
Le principe est d’utiliser une fonction de hachage (voir plus bas) afin de
localiser rapidement les paires (clé, valeur)
-
On crée un dictionnaire :
On initialise un tableau avec un grand nombre d’éléments tous identiques
Noneen Python, par exemple. -
On ajoute le couple
(clé, valeur):On calcule le hash de la
clé(en choisissant une fonction de hachage adaptée). Ce nombre devient l’indiceoù sera enregistré la paire.
Exemple
>>> contenu = [None] * 1024
>>> hachage('clé')
5
>>> contenu[5] = ('clé', 'valeur')
>>> contenu
[None, None, None, None, None, (clé, valeur), None, None, ...]
>>> contenu[ hachage(('clé')) ][ 1 ]
'valeur'
2. Implantation inefficace avec des listes #
Le principe est beaucoup plus simple.
Les données sont enregistrées dans une liste :
contenu = [('a', 1), ('b', 17), ...]
Pour chaque élément de contenu, par exemple ('a', 1), le premier élément
désigne la clé et le second la valeur. Ainsi a est la clé et 1 est la valeur.
Lors de l’ajout, on doit vérifier (en parcourant la liste) qu’elle ne contient
pas déjà une clé à ce nom.
La recherche est longue et nécessite un parcours.
Lors de l’accès à une valeur depuis sa clé, il faut encore parcourir la liste
afin de trouver le couple (clé, valeur). Là encore, ce parcours prend beaucoup
de temps.
En terme de complexité algorithmique, cette implantation est linéaire $O(n)$ où $n$ désigne le nombre d’éléments contenus. Le contrat n’est donc pas respecté !
3. Exemple d’implantation avec une table de hachage #
Cet exemple n’est pas une correction du TD précédent, il va plus loin et dépasse largement les attendus du programme.
À la fin on n’obtient pas exactement la même interface que celle proposée par les dictionnaires Python. La différence majeure est la taille maximale choisie arbitrairement (1024). Une fois qu’on dépasse cette taille, les collisions sont certaines et les données sont écrasées !
Néanmoins, elle présente une démarche intéressante et je vous invite à l’étudier comme approfondissement.
Les sources
'''
Implantation des dictionnaires en utilisant une table de hachage.
Objectif : accès aux valeurs en temps constant
On se limitera (pour l'instant) à 1024 éléments
'''
class DictionnaireHash:
'''Implantation des dictionnaires utilisant une table de hachage'''
TAILLE_MAX = 1024
def __init__(self, collection=None):
self.__cles_valeurs = [None] * self.TAILLE_MAX
self.__longueur = 0
if collection is not None:
for cle, valeur in collection:
self[cle] = valeur
def __calculer_indice(self, cle):
'''calcule l'indice d'un élément dans la liste `__cles_valeurs`'''
return hash(cle) % self.TAILLE_MAX
def est_vide(self):
'''prédicat vrai ssi le dictionnaire est vide'''
return len(self) == 0
def __setitem__(self, cle, valeur):
'''permet d'ajouter un élément avec 'd[cle] = valeur' '''
indice = self.__calculer_indice(cle)
self.__cles_valeurs[indice] = (cle, valeur)
self.__longueur += 1
def __getitem__(self, cle):
'''permet d'accéder à un élément avec 'd[cle]' -> 'valeur' '''
indice = self.__calculer_indice(cle)
contenu = self.__cles_valeurs[indice]
if contenu is not None:
return contenu[1]
raise KeyError(cle)
def __repr__(self) -> str:
'''renvoie une chaîne présentant le dictionnaire'''
if self.est_vide():
return 'DictionnaireHash()'
elems = tuple((elt for elt in self.__cles_valeurs if elt is not None))
return f'DictionnaireHash({elems})'
def __iter__(self):
'''permet d'itérer avec 'for cle in d' '''
for elt in self.__cles_valeurs:
if elt is not None:
yield elt[0]
def __delitem__(self, cle_recherchee):
'''permet d'effacer une paire avec 'del d[cle] ' '''
if self[cle_recherchee] is not None:
indice = self.__calculer_indice(cle_recherchee)
self.__cles_valeurs[indice] = None
self.__longueur -= 1
def values(self):
'''renvoie un iterateur des valeurs'''
return (elt[1] for elt in self.__cles_valeurs if elt is not None)
def keys(self):
'''renvoie un itérateur des clé'''
return (elt[0] for elt in self.__cles_valeurs if elt is not None)
def items(self):
'''renvoie un itérateur des couples (clé, valeur)'''
return (elt for elt in self.__cles_valeurs if elt is not None)
def clear(self):
'''vide le dictionnaire'''
self.__longueur = 0
self.__cles_valeurs = [None] * 1024
def copy(self):
'''retourne une copie du dictionnaire'''
items = [elt for elt in self.__cles_valeurs if elt is not None]
return DictionnaireHash(items)
def get(self, cle):
'''retourne la valeur de la clé si elle est contenue, None sinon'''
return self[cle] if cle in self else None
def __len__(self) -> int:
'''renvoie la longueur du dictionnaire avec 'len(d)' '''
return self.__longueur
def tester():
d = DictionnaireHash()
assert len(d) == 0
d[1] = 2
assert len(d) == 1
assert d[1] == 2
e = DictionnaireHash(((1, 2), (3, 4)))
assert e[1] == 2
assert e[3] == 4
assert repr(e) == 'DictionnaireHash(((1, 2), (3, 4)))'
assert len(e) == 2
assert [(k, e[k]) for k in e] == [(1, 2), (3, 4)]
assert [v for v in e.values()] == [2, 4]
assert 1 in d
del d[1]
assert 1 not in d
e.clear()
assert len(e) == 0
e = DictionnaireHash(((1, 2), (3, 4)))
f = e.copy()
assert repr(f) == 'DictionnaireHash(((1, 2), (3, 4)))'
e[1] = 5
assert repr(e) == 'DictionnaireHash(((1, 5), (3, 4)))'
assert e.get(7) is None
if __name__ == "__main__":
tester()
4. Le type dict
#
Python propose le type dict qui implémante tout ce qu’on peut attendre
d’une table de hachage. Il utilise la fonction native hash qui accepte
en paramètre tout objet non mutable et renvoie un entier.
Ici un petit rappel de la syntaxe.
__doc__ = '''
Dictionnaire en Python
Que peut-on faire avec un dictionnaire ?
'''
# 1. Créer un dictionnaire :
# vide
d1 = {}
d2 = dict()
# Avec des clés et valeurs
d3 = {'cle': 'valeur'}
# avec le nom de la classe, on doit passer un tuple contenant des tuples
d4 = dict((('cle1', 'valeur1'), ('cle2', 'valeur2')))
assert d4['cle1'] == 'valeur1'
assert d4['cle2'] == 'valeur2'
# 2. Accéder à un élément
assert d3['cle'] == 'valeur'
assert d3.get('cle') == 'valeur'
# si la clé n'est pas présente, la méthode get renvoie None
assert d3.get('bonjour') is None
try:
d3["bonjour"]
except KeyError as e:
# si la clé n'est pas présente, la notation d[cle] lève une exception KeyError"
pass
# 3. ajouter un élément
d3["bonjour"] = "aurevoir"
# la notation d[cle] = valeur appelle la méthode d.__setitem__(cle, valeur)
d3.__setitem__("1", "2")
assert d3["bonjour"] == "aurevoir"
# la notation d[cle] appelle d.__getitem__(cle)
assert d3.__getitem__("1") == "2"
# itérer sans préciser : sur les clés
print()
for cle in d3:
print("clé:", cle, " - valeur: ", d3[cle])
# itérer sur les clés
print()
for cle in d3.keys():
print("clé:", cle, " - valeur: ", d3[cle])
# itérer sur les valeurs
print()
for valeur in d3.values():
print("valeur: ", valeur)
# itérer sur les couples clés, valeurs
print()
for cle, valeur in d3.items():
print("clé:", cle, " - valeur: ", valeur)
# 4. Contient
assert "1" in d3
assert not 1 in d3
# 5. Longueur, comparaison
assert len(d4) == 2
assert d4 == {'cle1': 'valeur1', 'cle2': 'valeur2'}
# 6. Nettoyer, copier
d4.clear() # vide le dictionnaire
assert d4 == {}
d5 = d3.copy()
assert d3 == d5 # ils contiennent les mêmes éléments...
assert d3 is not d5 # mais sont des objets différents en mémoire
print("d3 et d5 sont des objets différents", id(d3), id(d5))
Compléments (hors programme) sur les fonctions de hachage #
1. Fonction de hachage #
On nomme fonction de hachage, de l’anglais hash function (hash : pagaille, désordre, recouper et mélanger) par analogie avec la cuisine, une fonction particulière qui, à partir d’une donnée fournie en entrée, calcule une empreinte numérique servant à identifier rapidement la donnée initiale, au même titre qu’une signature pour identifier une personne. Les fonctions de hachage sont utilisées en informatique et en cryptographie notamment pour reconnaître rapidement des fichiers ou des mots de passe.
1. Principe général #
Une fonction de hachage est typiquement une fonction qui, pour un ensemble de très grande taille (théoriquement infini) et de nature très diversifiée, va renvoyer des résultats aux spécifications précises (en général des chaînes de caractère de taille limitée ou fixe) optimisées pour des applications particulières.
2. Utilisation diverses #
On distingue deux types de fonctions de hachage :
-
Celles qui permettent de créer des dictionnaires rapides : la vitesse d’exécution doit alors être constante pour chaque donnée d’entrée
-
Les fonctions de hachage cryptographique Le critère fondamental est l’impossibilité à inverser la fonction.
>>> hash(???) 12345987Quelle est la donnée en entrée qui produit ce
hash?
Pour créer des dictionnaires, on n’a pas besoin d’obtenir TOUJOURS la même
sortie. Ainsi, lors de deux exécutions d’un même programme, la fonction python
hash ne renvoie pas les mêmes valeurs :
$ python -c "print(hash('a'))"
2976264172894533586
$ python -c "print(hash('a'))"
1904027818818373130
Par contre, durant une même exécution, la fonction hash renvoie toujours
la même valeur. Cette propriété permet :
- de créer des dictionnaires utilisant cette fonction
- de s’assurer qu’il est difficile de hacker la fonction et de provoquer des bugs.
L’utilisation des fonctions de hachage cryptographique est multiple, mais grosso modo, elles permettent de s’assurer qu’un contenu n’a pas été modifié.
Par exemple, lors de la publication d’un document, elles peuvent être employées pour le signer.
On publie le document important.pdf et sa signature (son hash) 9876786161
La personne qui télécharge le document calcule de son côté le hash avec la même fonction.
- Si elle trouve un hash différent, le document OU la signature ont été modifiés
- Si elle trouve le même hash, le document est beaucoup plus sûr.
L’édition d’un seul bit dans le document provoque un hash totalement différent :
$ echo "bonjour" | sha1sum
e7bc546316d2d0ec13a2d3117b13468f5e939f95 -
$ echo "bonjouR" | sha1sum
f6849d79cbdb3be947d586ba195fd4584107fa9c -
-
sha1est un algorithme de hachage cryptographique qui est maintenant désuet, il est toujours utilisé par Git pour créer un dictionnaire entre les noms de fichiers et leur contenu. -
Le meilleur algorithme de hachage cryptographique à ce jour est
sha256(ousha2) -
L’enregistrement sécurisé des mots de passe consiste justement… à ne pas enregistrer le mot de passe mais seulement son
hash.Lorsqu’on se connecte, le mot de passe est haché chez le client et seul le hash est transite sur le réseau (de manière sécurisé néanmoins).
Il est alors comparé avec le hash enregistré dans la BDD.
Cela rend impossible l’utilisation des données de la BDD pour se connecter si elle venait à être piratée. Il faudrait remonter jusqu’au mot de passe et c’est généralement très difficile.
2. La fonction hash de Python
#
Elle prend une unique paramètre (d’un type non mutable) et renvoie un entier.
Python l’utilise en interne pour la structure de donnée dict
>>> {[1], 2} # plante parce que la clé '[1]' est une liste mutable
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: unhashable type: 'list'
En interne elle appelle la méthode __hash__ du type d’entrée.
Mais comment c’est programmé en interne ?
Comme le reste des fonctions natives, le code est en C.
Cette discussion (en anglais) aborde justement cet aspect. Grosso modo, chaque type d’objet natif dispose de sa propre fonction. Par exemple, celui des tuples qui fait 1000 lignes de C… La liste des contributeurs fait apparaître plusieurs ‘célébrités’ de Python (Guido Von Rossum, Raymond Hettinger, Tim Peters etc.)
Bref, c’est tout sauf simple.
Fonction de hachage cryptographique #
Une fonction de hachage cryptographique est une fonction de hachage qui, à une donnée de taille arbitraire, associe une image de taille fixe, et dont une propriété essentielle est qu’elle est pratiquement impossible à inverser, c’est-à-dire que si l’image d’une donnée par la fonction se calcule très efficacement, le calcul inverse d’une donnée d’entrée ayant pour image une certaine valeur se révèle impossible sur le plan pratique. Pour cette raison, on dit d’une telle fonction qu’elle est à sens unique.
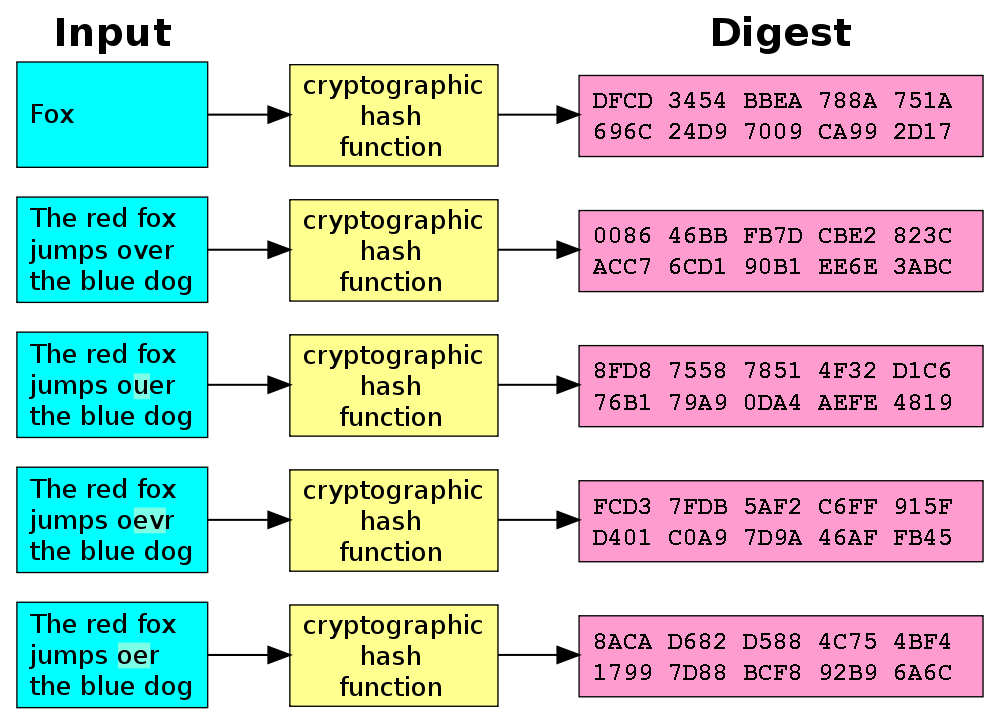
Une fonction de hachage cryptographique idéale possède les quatre propriétés suivantes :
- la valeur de hachage d’un message se calcule « très rapidement » ;
- il est, par définition, impossible, pour une valeur de hachage donnée, de construire un message ayant cette valeur de hachage ;
- il est, par définition, impossible de modifier un message sans changer sa valeur de hachage ;
- il est, par définition, impossible de trouver deux messages différents ayant la même valeur de hachage.
Exemples de fonctions de hachage cryptographique #
-
MD5 est souvent utilisé pour vérifier qu’un fichier n’a pas été altéré.
Cette fonction n’est plus sûre depuis des décénies
-
SHA dispose de plusieurs variantes.
- SHA0 et SHA1 ne sont plus sures mais ont toujours des usages (GIT utilise SHA1 pour comparer les fichiers)
- SHA2 est celle utilisée partout en pour enregister les mots de passe etc.
- SHA3 repose sur un autre algorithme (fonction éponge) et n’est pas encore utilisée partout. Cela sera peut-être le cas d’ici une dizaine d’années.
Description rapide de SHA2 #
Les entrées de la fonction de compression sont découpées
- en mots de 32 bits pour SHA-256 et SHA-224,
- en mots de 64 bits pour SHA-512 et SHA-384.
La fonction de compression répète les mêmes opérations un nombre de fois déterminé, on parle de tour ou de ronde, 64 tours pour SHA-256, 80 tours pour SHA-512.
Chaque tour fait intervenir comme primitives l’addition entière pour des entiers de taille fixe, soit une addition modulo 232 ou modulo 264, des opérations bit à bit (opérations logiques, décalages avec perte d’une partie des bits et décalages circulaires), et des constantes prédéfinies, utilisées également pour l’initialisation.
Avant traitement, le message est complété par bourrage de façon que sa
longueur soit un multiple de la taille du bloc traité par la fonction de
compression.
Le bourrage incorpore la longueur (en binaire) du mot à traiter :
c’est le renforcement de Merkle-Damgård, ce
qui permet de réduire la résistance aux collisions de la fonction de hachage à
celle de la fonction de compression. Cette longueur est stockée en fin de
bourrage sur 64 bits dans le cas de SHA-256 (comme pour SHA-1), sur 128 bits
dans le cas de SHA-512, ce qui « limite » la taille des messages à traiter à
264 bits pour SHA-256 (et SHA-224) et à 2128 bits pour SHA-512 (et SHA-384).